Como já devem ter percebido adoro ajudar os meus amigos, neste caso o meu grande amigo query optimizer do SQL Server.
Vamos lá analisar mais uma maneira de o ajudar?
Um caso com que me deparo algumas vezes é o facto de nós sabermos algumas coisas sobre os nossos dados que ainda não explicámos bem ao SQL Server.
Por exemplo, temos uma coluna numa tabela em que sabemos só poderem lá estar um valor dentro de uma lista.
Claro que isto poderia e deveria ser resolvido com outro tipo de abordagem, levando esta coluna para uma tabela e criando uma relação, por exemplo. Mas isso é tópico para outras conversas…
Imaginem este simples caso naquelas tabelas lindas que fazemos só para demos.
create table ConstraintDemo02_base ( id int identity(1,1) , ConstrainedColumn char(1) , AnotherColumn int , FillColumn char(100) default 'Just to fill it up' ) go
Vamos lá meter alguns valores, mesmo que seja da maneira mais parva que nos ocorre.
insert into ConstraintDemo02_base (AnotherColumn) select ABS(CHECKSUM(NEWID()))%10000 from sys.objects a cross join sys.objects b cross join sys.objects c update ConstraintDemo02_base set ConstrainedColumn = case when AnotherColumn %5 = 0 then 'A' when AnotherColumn %5 = 1 then 'B' when AnotherColumn %5 = 2 then 'C' when AnotherColumn %5 = 3 then 'D' else 'E' end
Temos então um id sequencial, um campo que apenas tem um de 5 possíveis caracteres, um inteiro qualquer e uma coluna “para encher”.
Vamos correr lá algumas queries e ver o que o nossos planos de execução, tempos e reads nos vão dizer.
set statistics time, io on select * from ConstraintDemo02_base where ConstrainedColumn = 'A'

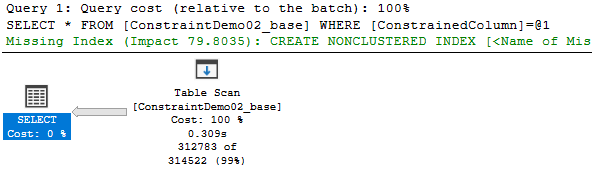
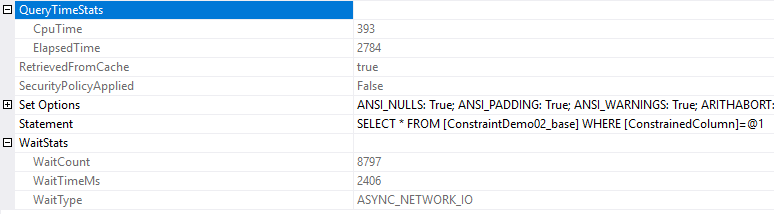
Tudo normal, scan à heap que demora 0.3s, tempo total 2784 contando com os 2,4s que demorámos a receber os dados todos (que aparecem no ASYNC_NETWORK_IO).
Missing index na ConstrainedColumn com as outras colunas incluídas, porque “select *” assim o obriga.
E se fizermos uma coisa que, neste caso, sabemos ser exactamente igual?
select *
from ConstraintDemo02_base
where ConstrainedColumn not in ('B', 'C', 'D', 'E')

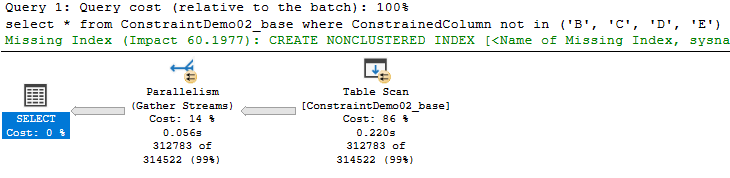
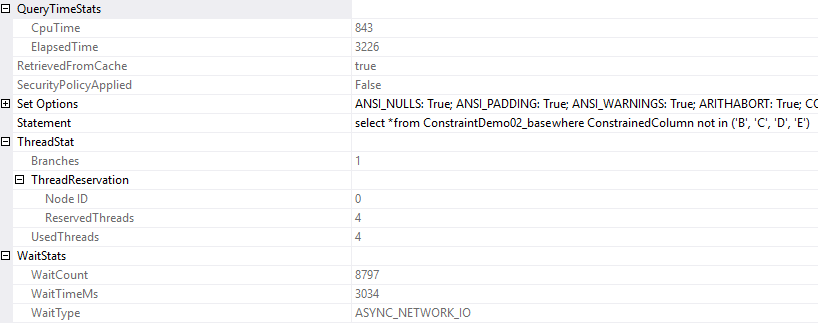
Algumas diferenças. O cost threshold for paralelism deve ter sido alcançado, logo temos um plano paralelizado, com 4 threads usados.
Temos o mesmo número de logical reads mas vemos o que o scan count agora é 5.
De resto não há grandes diferenças.
Vamos experimentar sem paralelismo?
select *
from ConstraintDemo02_base
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
option (maxdop 1)

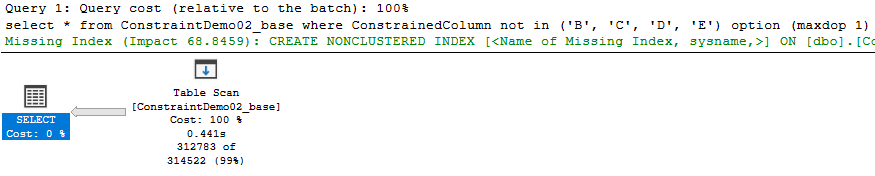
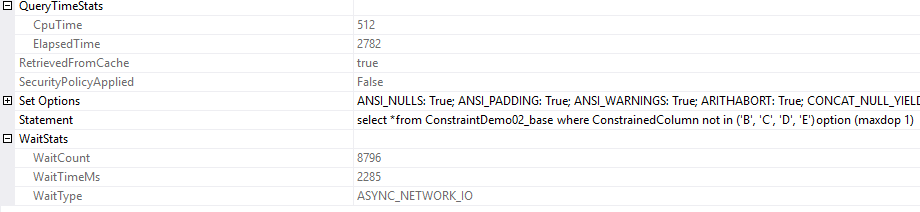
Voltámos ao caso anterior, scan count igual a 1 e os mesmos logical reads.
E se dessemos uma ajuda ao nosso amigo SQL Server?
Sabemos que a coluna apenas pode ter estes 5 valores. Nós sim, mas o optimizer não.
Vamos copiar a tabela mas sendo uns gajos porreiros e colocando uma check constraint.
select *
into ConstraintDemo02_checked
from ConstraintDemo02_base
alter table ConstraintDemo02_checked
add constraint ConstrainedColumn_Values
check ( ConstrainedColumn in ('A', 'B', 'C', 'D', 'E'))
Vamos lá outra vez?
select *
from ConstraintDemo02_checked
where ConstrainedColumn = 'A'
select *
from ConstraintDemo02_checked
where ConstrainedColumn not in ('B', 'C', 'D', 'E')

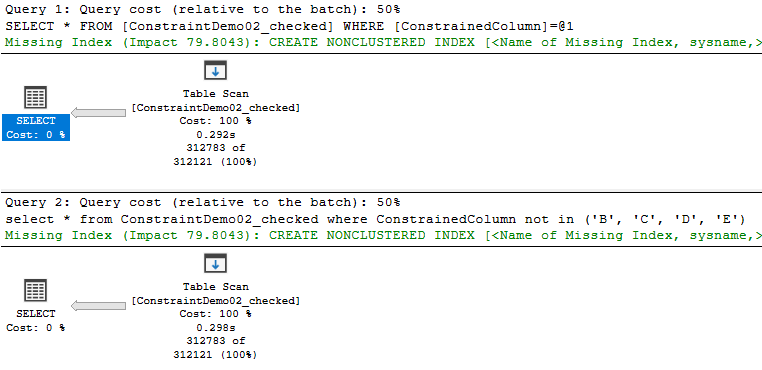
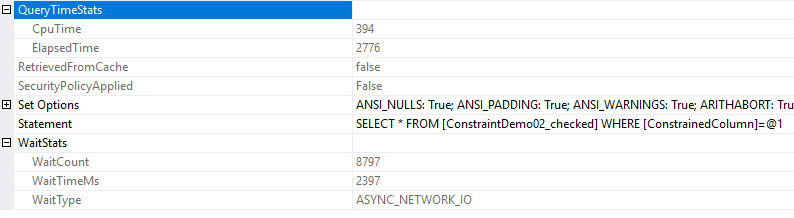
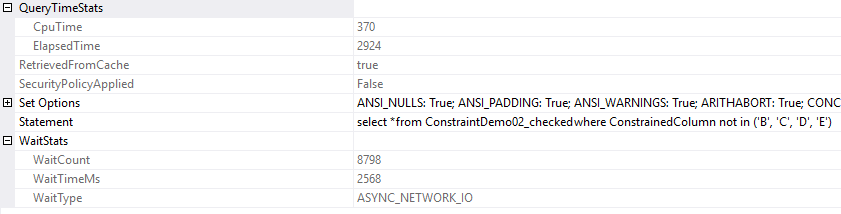
Não vemos nenhuma diferença à primeira vista.
Isso quer dizer que não há diferenças?
Uma grande é que a query com not in já não corre paralelizada como nas execuções anteriores. Porque será?
Vamos analisar o que cada scan faz.
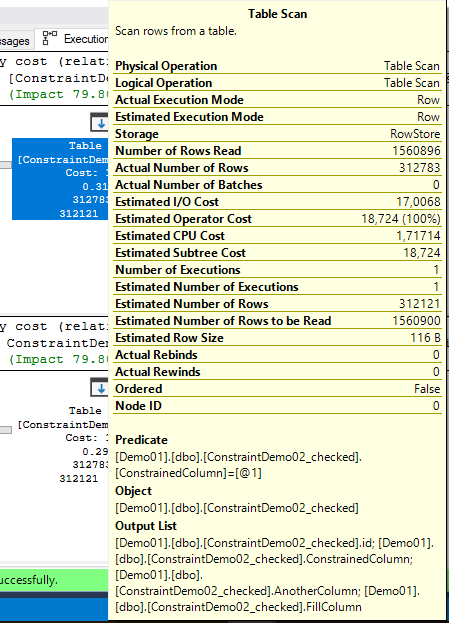
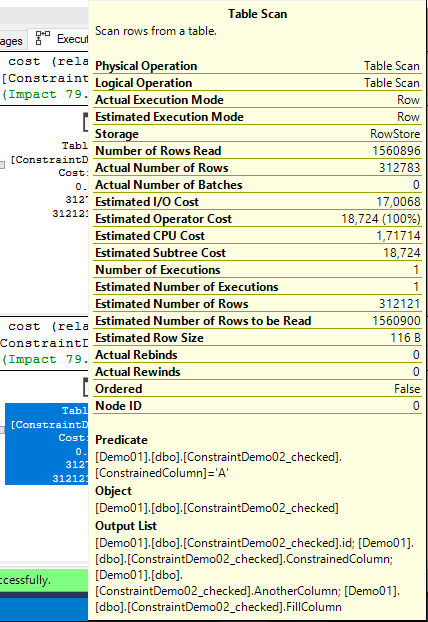
Notam que na segunda query o optimizer procura por ‘A’ em vez de procurar onde é diferente de ‘B’, ‘C’, ‘D’, ‘E’?
Vamos voltar a correr na tabela sem a check constraint para vermos a diferença.
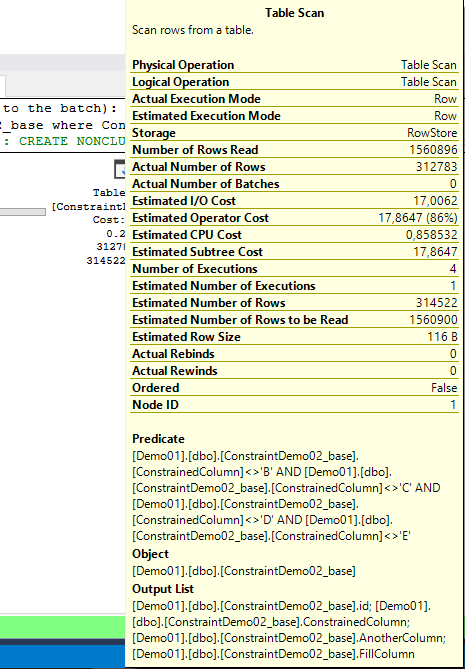
Pois é… antes ele procurava pelas diferentes, agora sabe que só podem ser ‘A’. E usa isso nosso favor.
Mas podemos usufuir muito mais desta simplificação. Mais à frente já vemos como.
Antes disso… e se com índices fosse suficiente? Onde é que já vi isto antes…
select *
into ConstraintDemo02_indexed
from ConstraintDemo02_base
create unique clustered index ucidx on ConstraintDemo02_indexed (id)
create nonclustered index ncidx on ConstraintDemo02_indexed (ConstrainedColumn)
select *
from ConstraintDemo02_indexed
where ConstrainedColumn = 'A'
select *
from ConstraintDemo02_indexed
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
select *
from ConstraintDemo02_indexed
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
option (maxdop 1)


Prefere fazer scan à nossa tabela… maldito “select *”.
Mais uma voltinha, agora com uma query coberta pelo índice nonclustered.
select id, ConstrainedColumn
from ConstraintDemo02_indexed
where ConstrainedColumn = 'A'
select id, ConstrainedColumn
from ConstraintDemo02_indexed
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
select id, ConstrainedColumn
from ConstraintDemo02_indexed
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
option (maxdop 1)


Desta vez tudo é diferente.
Reads entre 428, 1726 e 2129.
Um seek, um seek paralelizado e um scan (!) ao nosso nonclustered.
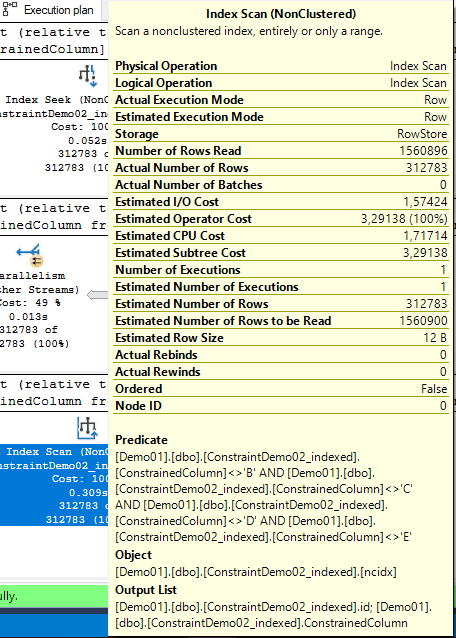
Vamos analisar os predicados nos operadores?

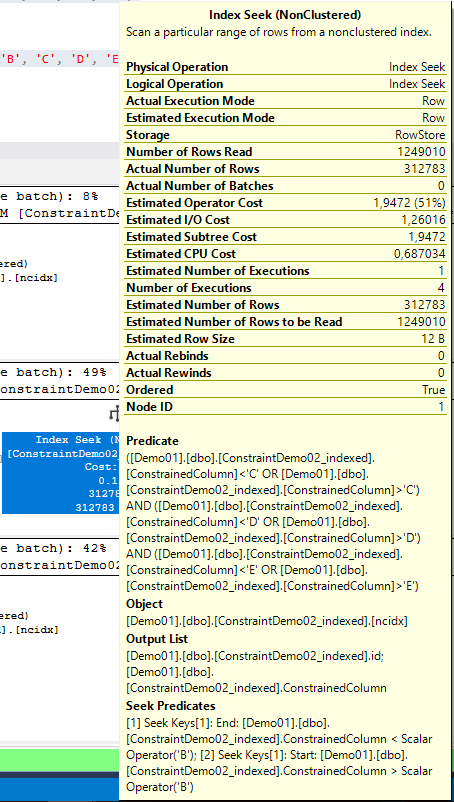
Seek ao parâmetro, neste caso o ‘A’ que foi parametrizado.
Seek com residual predicate. Procura antes de ‘B’ e depois de ‘B’, sendo que a este último vai depois filtrar pelos valores restantes.
Scan retornando todos os valores diferentes.
Vamos agora experimentar com uma tabela indexada e com a check constraint?
select *
into ConstraintDemo02_indexed_checked
from ConstraintDemo02_base
create unique clustered index ucidx on ConstraintDemo02_indexed_checked (id)
create nonclustered index ncidx on ConstraintDemo02_indexed_checked (ConstrainedColumn)
alter table ConstraintDemo02_indexed_checked
add constraint ConstraintDemo02_indexed_checked_ConstrainedColumn
check ( ConstrainedColumn in ('A', 'B', 'C', 'D', 'E'))
select id, ConstrainedColumn
from ConstraintDemo02_indexed_checked
where ConstrainedColumn = 'A'
select id, ConstrainedColumn
from ConstraintDemo02_indexed_checked
where ConstrainedColumn not in ('B', 'C', 'D', 'E')

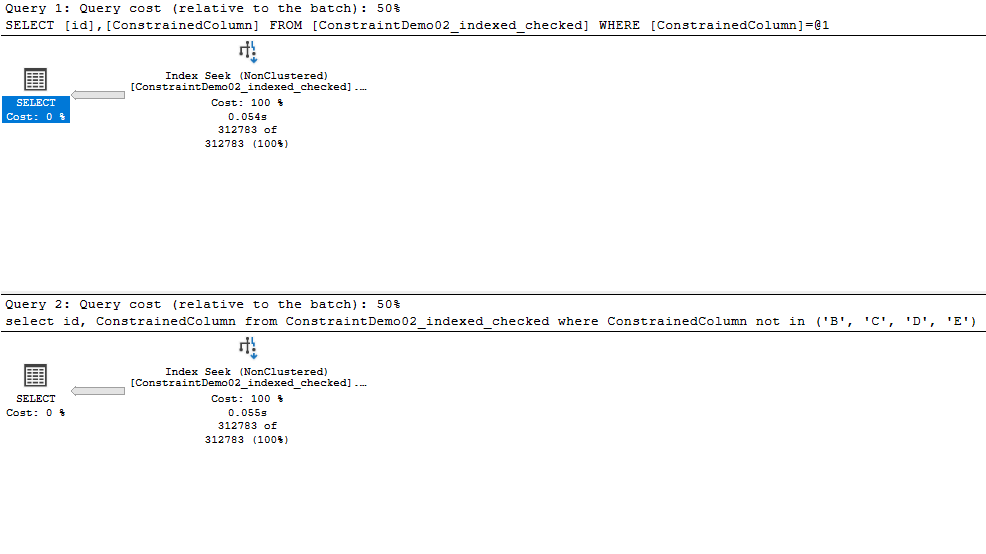
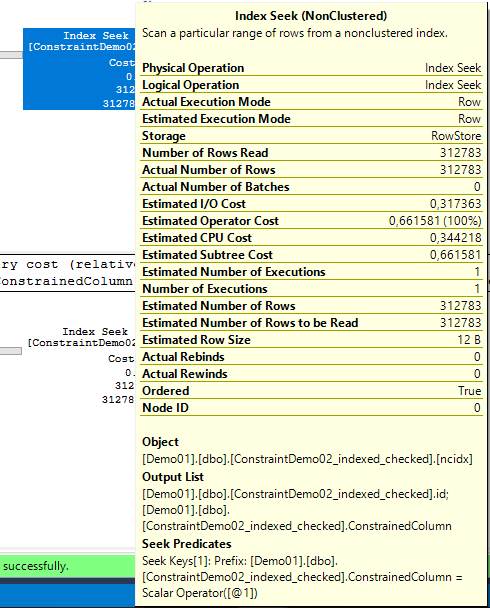
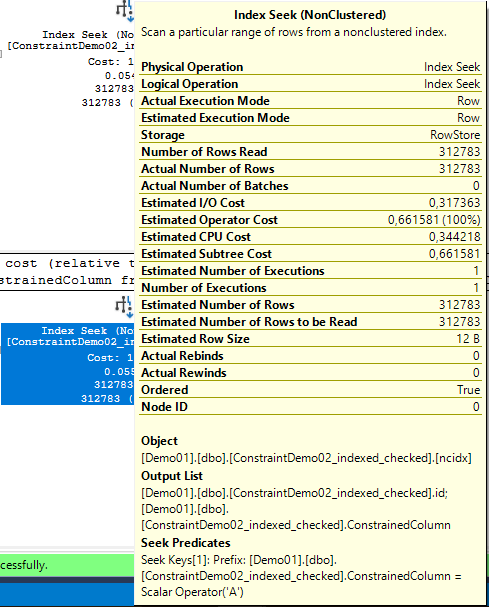
O mesmos reads, 428.
Mesmo plano de execução, com seek ao nosso nonclustered.
Na segunda query ele sabe que o que queremos são só as colunas com ‘A’.
Vamos analisar as diferenças do “not in” entre as tabelas que fomos criando?
select id, ConstrainedColumn
from ConstraintDemo02_base
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
select id, ConstrainedColumn
from ConstraintDemo02_checked
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
select id, ConstrainedColumn
from ConstraintDemo02_indexed
where ConstrainedColumn not in ('B', 'C', 'D', 'E')
select id, ConstrainedColumn
from ConstraintDemo02_indexed_checked
where ConstrainedColumn not in ('B', 'C', 'D', 'E')


O que vemos é esperado.
Nos planos de execução vemos que nas queries sobre as tabelas não indexadas temos um missing index recomendation, que naturalmente desaparece nas indexadas.
Quando temos a tabela indexada e com a coluna com a check constraint o custo baixa ao ponto de não ultrapassar o cost threshold for paralelism e ser usado um plano série.
Os reads passam de quase 23k quando não temos índice para quase 2k quando temos índice. Já a check constraint faz maravilhas e fazemos menos de 500.
Extrapolando para as nossas tabelas e queries de produção… É uma boa ajuda, ou não? (Até rima!)


